
Robuuste plekherkenning vir visie-gebaseerde SLAM-stelsels met behulp van semantiese inligting
- Hierdie blog bespreek ’n nuwe metode om plekherkenning in visie-gebaseerde SLAM-stelsels te verbeter deur semantiese inligting te gebruik. In plaas daarvan om net op geometriese punte staat te maak, kombineer die SeM2DP-benadering 3D-data met objekherkenning om ’n meer betekenisvolle voorstelling van ’n toneel te skep.
- Die resultate wys dat hierdie metode meer akkuraat is en minder data benodig as tradisionele tegnieke, alhoewel dit tans stadiger is.
- Uiteindelik toon die navorsing dat robotte beter kan navigeer en meer betroubare kaarte kan bou wanneer hulle nie net vorms herken nie, maar ook die konteks en betekenis van hul omgewing verstaan.
Stel jou voor jy ry in ’n nuwe stad met ’n GPS wat stadig van koers afwyk. Elke paar blokke sal jy ’n landmerk nodig hê, soos die stadsaal, om jou posisie weer reg te stel. Robotte het dieselfde probleem.
In visuele gelyktydige lokalisering en kartering (SLAM) bou ’n robot ’n kaart terwyl dit terselfdertyd bepaal waar dit is. Elke keer as dit ’n plek weer besoek, kan dit die “lus sluit”, opgehoopte fout verwyder en sy kaart akkuraat hou. Die uitdaging? Akkurate lus-sluiting begin by die vermoë om te herken dat die toneel voor die kamera dieselfde is as een wat vroeër gesien is.
Die meeste lus-sluitstelsels behandel ’n toneel as ’n versameling geometriese punte. Hulle pas hoeke, rande of dieptepunte by mekaar, maar ignoreer wat daardie punte eintlik voorstel: ’n motor, ’n padteken, ’n boom. Mense, daarenteen, maak sterk staat op semantiek—die voorwerpe self en hul verhoudings.
Die tesis van March Brian Strauss, onder toesig van dr. Corne Van Daalen, stel die vraag: kan die insluiting van hierdie semantiese inligting in die wiskunde robotte dieselfde voordeel gee?
Die SeM2DP-idee in een sin
Kombineer ’n yl 3D-puntwolk vanaf ’n stereokamera met pixelvlak-objeketikette vanaf ’n neurale netwerk, en druk dit saam in ’n kompakte 256-getal “vingerafdruk” genaamd Semantic Multiview 2-D Projection (SeM2DP).
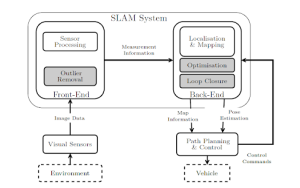
Figuur 1: ’n Blokdiagram van ’n generiese, visie-gebaseerde SLAM-stelsel
Hoe dit werk (sonder vergelykings)
Sien die wêreld in 3D
Twee kameras langs mekaar neem ’n stereo-beeldpaar. Klassieke kenmerkdetektors (SIFT werk die beste) identifiseer unieke pixels, pas hulle oor die twee beelde, en bereken hul 3D-posisies.
Etiketteer die pixels
’n Vooraf-opgeleide MobileNetV2-neurale netwerk ken vinnig ’n klas aan elke pixel toe—pad, motor, gebou, lug, ensovoorts.
Kombineer geometrie en betekenis
Elke 3D-punt erf die etiket van die pixel waaruit dit ontstaan het. Die resultaat is ’n “semantiese puntwolk”: punte met konteks.
Projeksie en groepering
SeM2DP verdeel hierdie puntwolk in verskeie virtuele kamera-aansigte, omskep elke aansig in histogramme wat beide ligging en dominante etikette vasvang, en kombineer dit in ’n enkele 256-waarde vektor.
Vinnige vergelyking
Nuwe vektore word met mekaar vergelyk deur ’n k-naaste-bure-soektog te gebruik. ’n Goeie passing dui aan: “Ek was al hier”, wat lus-sluiting aktiveer.
Omdat die vingerafdruk klein is, bly berging en vergelyking doeltreffend, selfs wanneer duisende plekke gestoor word.
Werk dit werklik beter?
Strauss het SeM2DP op vyf standaard KITTI stereo-odometrie datastelle getoets en dit vergelyk met twee gevestigde beskrywingsmetodes:
Beskrywer | Gem. gemiddelde presisie (mAP) | Vektorlengte (waardes) |
SeM2DP | 0.81 | 256 |
Colour-M2DP | 0.78 | 576 |
Original M2DP | 0.50 | 192 |
Belangrike bevindings
- Hoër akkuraatheid: SeM2DP presteer beter as die kleurgebaseerde metode in 3 van die 5 gevalle en is aansienlik beter as die geometrie-alleen metode in almal.
- Minder berging: Dit lewer beter resultate met minder as die helfte van die data.
- Stadiger verwerking: Die volle proses neem ongeveer twee keer so lank (ongeveer 0.5 sekondes per stereo-paar op ’n CPU), hoofsaaklik weens semantiese segmentering.
Hoekom die stadiger spoed soms die moeite werd is
Indien ’n robot reeds neurale netwerke gebruik vir objekvermyding, is die segmenteringsstap basies “gratis”, aangesien dieselfde data hergebruik word. In daardie geval kry jy ’n sterker en meer robuuste plekherkenning teen minimale ekstra koste.
Strauss wys daarop dat robotika toenemend fokus op dieper toneelbegrip, wat hierdie benadering prakties maak.
Daar is egter nog verbeterings moontlik:
- Spoed: Omskakeling na C++ en parallelle verwerking kan werkverrigting verbeter
- Volledige integrasie: Verdere toetsing binne ’n volledige SLAM-stelsel
- Dinamiese tonele: Meer navorsing benodig waar baie voorwerpe beweeg
Slotgedagtes
Hierdie navorsing toon dat robotte aansienlik beter kan presteer wanneer hulle konteks verstaan, nie net vorms nie. SeM2DP kombineer 3D-geometrie met semantiese inligting om ’n kompakte en akkurate voorstelling van plekke te skep.
Hoewel dit tans stadiger is, bied dit groot voordele:
- meer akkurate kaarte
- minder navigasiefoute
- en beter omgewingsbegrip
Dit is ’n belangrike stap na masjiene wat hul wêreld meer soos mense kan interpreteer.
Laai en lees die volledige navorsingsartikel hier: https://scholar.sun.ac.za/items/ffb2f4e6-7a82-4b12-8395-8b408099708d
Verwante stories

Ingenieurswese en tegnologie
’n Slimmer Manier om Huisenergie Tydens Beurtkrag te Bestuur
Vir baie Suid-Afrikaanse huishoudings met sonpanele en batterye lê die moeilike deel nie by die installasie van die hardeware nie. Die moeiliker deel is om te...

Ingenieurswese en tegnologie
Wanneer Mobiele Netwerke Misluk, Kan ’n Foon Jou Groep Steeds Bereik
By ’n konsert, sportbyeenkoms of buiteluggeleentheid neem mense dikwels aan dat hul fone sal werk wanneer hulle dit nodig kry. In die praktyk kan dit vinnig...

Ingenieurswese en tegnologie
Ingenieurswese Opedag in ’n heringerigte spasie
Grys wolke en ’n donderstorm het min impak gehad om voornemende studente en hulle gesinne te ontmoedig om die 2026-weergawe van die Fakulteit Ingenieurswese se...