
Outonome Ren op Onbekende Bane met Versterkingsleer
- Die navorsing ondersoek hoe versterkingsleer gebruik kan word om outonome voertuie teen hoë spoed te laat jaag op onbekende bane. In plaas van vooraf gekarteerde roetes, gebruik die stelsel intydse LiDAR-data om besluite te neem.
- ’n Nuwe metode verbeter stabiliteit en beheer, wat lei tot beter werkverrigting en meer konsekwente bestuur. Die model presteer uitstekend in simulasies en pas maklik aan by nuwe bane en hindernisse.
- Werklike toetse wys dat die stelsel betroubaar oordra van simulasie na die regte wêreld, sonder ekstra opleiding. Die navorsing toon dat versterkingsleer ’n buigsame en doeltreffende alternatief vir tradisionele outonome bestuursmetodes is.
Devin Jefferies, ’n Meestersgraadstudent in Ingenieurswese aan Stellenbosch Universiteit, het navorsing aangebied—onder leiding van Dokters JC Schoeman en Benjamin Evans—oor hoe om ’n kunsmatige intelligensie te leer om te jaag. Sy werk fokus op ’n spesifieke uitdaging: hoe om ’n outonome motor teen sy maksimum vermoë te laat ry op ’n baan wat dit nog nooit gesien het nie. Die navorsing het ook die agent se prestasie gedokumenteer toe dit van ’n simulasie na ’n fisiese voertuig oorgedra is.
Die Ingenieursuitdaging
Die veld van outonome ren is ’n toetsgrond vir voertuigbeheerstelsels. Baie stelsels maak staat op “klassieke beheer-metodes”. Hierdie benaderings vereis presiese kaarte van die renbaan om vooraf ’n optimale roete te beplan. Hulle kan baie konsekwent wees, maar hul afhanklikheid van voorafbeplande roetes beperk hulle tot “bekende, statiese omgewings”. ’n Voertuig wat hierdie metode gebruik, kan nie maklik aanpas by ’n baan waarvoor dit nie ’n kaart het nie, of by skielike hindernisse.
’n Alternatief is diep versterkingsleer (DRL). Hierdie algoritmes leer meer soos ’n mens, deur ’n proses van proef en fout. Hulle benodig nie voorafbeplande trajekte nie. In teorie maak dit hulle beter geskik om te veralgemeen na nuwe situasies, soos onbekende bane. Die grootste nadeel was egter prestasie—DRL-algoritmes was tipies stadiger en minder konsekwent as klassieke metodes.
Jefferies se navorsing het daarop gemik om hierdie prestasiegaping te verklein. Die doel was om ’n DRL-agent te ontwikkel wat kan veralgemeen na nuwe bane, terwyl dit steeds die hoëspoedprestasie van tradisionele, kaartgebaseerde metodes ewenaar.
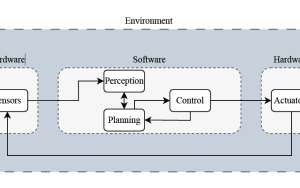
Figuur 1: ’n Moontlike implementering van die outonome bestuurspyplyn, waar die swart pyle die vloei van inligting aandui.
’n “Sentre-georiënteerde” Oplossing
Die navorsing stel ’n “end-tot-end” renraamwerk bekend. Die metode staan bekend as die “centre-orientated twin delayed deep deterministic policy gradient” (CO-TD3) agent. Dit werk deur rou sensormetings vanaf ’n LiDAR (’n lasergebaseerde skandeerder) direk na die agent se netwerk te stuur, wat dan opdragte uitvoer om die voertuig se spoed en stuurhoek te beheer.
’n Algemene probleem met DRL-renagente is onstabiele stuurgedrag, beskryf as ’n “slingerende en rukkerige beweging”. Dit gebeur wanneer die agent oor-korrigeer—te naby aan een muur beweeg en dan weer oorkorrigeer na die ander kant.
Jefferies se navorsing het ’n oplossing hiervoor geïdentifiseer. Hy het ’n “sentreringsterm” ontwikkel en dit by die agent se toestandsvektor gevoeg (die stel inligting wat dit gebruik om besluite te neem).
Hierdie sentreringsterm is nie ’n voorafbeplande kaart nie.
Dit word in werklike tyd bereken met behulp van die lewendige LiDAR-skandering.
Dit word bepaal deur die eerste drie en laaste drie afstandstrale van die 180-grade LiDAR-skandering te gemiddeld.
Hierdie berekening gee die agent ’n konstante aanduiding van hoe ver dit van die middel van die baan af is.
Hierdie nuwe inligting, saam met ’n beloningsfunksie wat die agent straf wanneer dit van die middel afwyk en beloon vir vinnige, volledige rondtes, het die voertuig se gedrag gestabiliseer. Die navorsing het bevind dat hierdie toevoeging die konsekwentheid van die agent se besluite verbeter het.
Om die agent se vermoë om te veralgemeen te toets, het Jefferies ook ’n “ewekansige baangenerator” ontwikkel. Hierdie hulpmiddel skep ’n verskeidenheid nuwe en uitdagende bane, wat voorkom dat die agent bloot opleidingsbane memoriseer.
Prestasie in Simulasie
Die CO-TD3-agent is in die F1TENTH-simulator getoets teen verskeie maatstawwe op vier standaardbane. Die prestasie was nie net stabiel nie—dit was vinnig.
Op die “AUT” (Oostenryk) baan was die vinnigste rondtetyd 15.51 sekondes. Dit was vinniger as klassieke metodes soos “Opti. & tracking” (16.79 s) en “MPCC” (16.87 s). Die agent het ook beter gevaar as ander DRL-metodes op al die getoetste bane.
Die hoofdoel—veralgemening—is daarna getoets. Die agent is op een baan (“MCO”) opgelei en daarna op 50 nuwe, ewekansige bane getoets:
- CO-TD3-agent: 100% voltooiingskoers teen ’n maksimum spoed van 8 m/s
- Standaard TD3-agent: 46.67% voltooiingskoers teen ’n stadiger 4 m/s
Die CO-TD3-agent kon ook nuwe, ewekansige hindernisse vermy, selfs sonder spesifieke opleiding daarvoor.
Van Simulasie na Werklikheid
Die finale toets was om die agent van die simulasie na ’n fisiese F1TENTH-voertuig oor te dra. Hierdie stap onthul dikwels probleme, aangesien werklike sensors en motors nie so ideaal soos simulasies is nie.
Jefferies het die agent in simulasie opgelei en die geleerde parameters na die werklike voertuig oorgedra.
Sonder verdere opleiding het die agent ’n 100% voltooiingskoers op die fisiese baan behaal, met prestasie wat nou ooreenstem met die simulasie:
- Werklike baan 1: Simulasie 6.44 s | Werklik 6.45 s
- Werklike baan 2: Simulasie 6.60 s | Werklik 6.75 s
Hierdie sukses is ook met veralgemening herhaal. Die agent is op ’n ander baan opgelei en toe op ’n onbekende fisiese baan geplaas. Dit het die rondte suksesvol voltooi in 6.27 sekondes.

Figuur 2: Beelde van die toetsopstelling met die werklike voertuig.
Implikasies en Toekomstige Werk
Hierdie navorsing wys dat ’n goed ontwerpte DRL-agent kan meeding met, en in sommige gevalle beter presteer as, klassieke kaartgebaseerde algoritmes. Die vermoë om ’n algemene bestuursbeleid aan te leer, eerder as om ’n voorafbepaalde plan te volg, is die belangrikste verskil.
Hierdie werk open nuwe moontlikhede vir meer dinamiese probleme, soos kop-aan-kop renne, waar voorafbeplande roetes onvoldoende is. Hierdie tipe algoritmes kan in die toekoms gebruik word in gemengde stedelike verkeer, waar voertuie op nuwe situasies moet reageer sonder ’n voorafbepaalde plan.
Laai en lees die volledige navorsing: https://scholar.sun.ac.za/items/43e6d233-2024-46d0-9ae8-ba3029360954
Verwante stories

Ingenieurswese en tegnologie
’n Slimmer Manier om Huisenergie Tydens Beurtkrag te Bestuur
Vir baie Suid-Afrikaanse huishoudings met sonpanele en batterye lê die moeilike deel nie by die installasie van die hardeware nie. Die moeiliker deel is om te...

Ingenieurswese en tegnologie
Wanneer Mobiele Netwerke Misluk, Kan ’n Foon Jou Groep Steeds Bereik
By ’n konsert, sportbyeenkoms of buiteluggeleentheid neem mense dikwels aan dat hul fone sal werk wanneer hulle dit nodig kry. In die praktyk kan dit vinnig...

Ingenieurswese en tegnologie
Ingenieurswese Opedag in ’n heringerigte spasie
Grys wolke en ’n donderstorm het min impak gehad om voornemende studente en hulle gesinne te ontmoedig om die 2026-weergawe van die Fakulteit Ingenieurswese se...